Adaptive LTSM Models with Generative AI
If you haven’t heard, Generative AI is coming for our jobs, and given that most of my work is creating problems that I have to solve myself later I would say it is already here for mine.
So, to get on the hype train and to learn more about Large Language Models and how to use them, I have come up with a combination of passions for a project.
Machine Learning and losing money on the Stock Market.
I am going to train a model to predict the closing price of a single stock, while incorporating a LLM to generate and improve the model’s prediction accuracy based on scores from previously generated code.
Sounds complicated but the process is relatively simple.
The Plan
I am going to setup the model to train and predict the closing price 7 days in advance.
There are a few things that are required to make that work.
First there is the dataset, as this is mainly focused on the use of an LLM to generate a functional model I will provide a simple dataset to the model to be trained on, which will include the open and closing price, as well as a few technical indicators I have chosen.
There is no reason that later, once a good baseline model has been generated, that the dataset code couldn’t also be generated by a LLM.
There will need to be an LLM “agent” that is in control of generating the model that is trained.
And some form of training loop that takes the model, trains it, and returns a score that can be passed back to the LLM which will use the score to modify the code, hopefully increasing the performance of the prediction model.

The Dataset
So, the easiest way to get historic data is from the yfinance python package (did I mention I am coding this in python?)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
import ta
import talib
import datetime
import yfinance as yf
def generate_dataset(ticker):
end_date = datetime.date.today().strftime("%Y-%m-%d") #end date for our data retrieval will be current date
start_date = '2010-01-01' # Beginning date for our historical data retrieval
df = yf.download(ticker, start=start_date, end=end_date)
# TA Functions
df['RSI'] = ta.momentum.rsi(df['Adj Close'])
df['RSI'] = pd.to_numeric(df['RSI'], errors='coerce')
df['MACD'] = ta.trend.macd(df['Adj Close'])
df['RSI'] = talib.RSI(df['Adj Close'], timeperiod=14)
df['Pct Change'] = df['Adj Close'].pct_change()
df['20MA'] = df['Adj Close'].rolling(20).mean()
df['50MA'] = df['Adj Close'].rolling(50).mean()
df['100MA'] = df['Adj Close'].rolling(100).mean()
indicator_bb = ta.volatility.BollingerBands(close=df["Close"], window=20, window_dev=2)
df['bb_bbm'] = indicator_bb.bollinger_mavg()
df['bb_bbh'] = indicator_bb.bollinger_hband()
df['bb_bbl'] = indicator_bb.bollinger_lband()
df['Lag_1'] = df['Adj Close'].shift(1)
df['Lag_2'] = df['Adj Close'].shift(2)
df['Lag_3'] = df['Adj Close'].shift(3)
df.dropna(inplace=True)
return df
A lot (all) of the technical indicators are just arbitrary, the lags was mainly to increase the size of the training dataset.
I am tracking the adjusted close price to make my life a bit easier, as well as get rid of the jumps in price from any stock splits that may have occurred.
The Agent
So, now the fun part, getting an LLM to spit out code with the right formatting, the right imports, the right indentation and with real code that it just didn’t make up for fun and to be a silly bugger.
I am going to use Ollama to run the model on my machine, just as a basic chat that I will be jamming full of context, instructions, code and score that definitely won’t limit me later.
I have done a little testing with models and I had the least amount of pain getting to output python that wasn’t completely messed up while still providing improvements on the model was yi-coder specifically Yi-Coder-9B to fit on my tiny GPU VRAM.
A larger LLM or LLMaaS could improve the output model but in my limited testing the model I chose was good enough.
The Prompt
Another thing I am still very much learning is how to construct a prompt to get out what I want, which could open up the project to more complex and larger LLMs in the future.
The system prompt I’ll provide to yi-coder that has a pretty low error rate, reducing the need for debugging/error correction.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class MLEngineer:
SYSTEM_PROMPT="""You're a python machine learning expert that is creating a model to predict stock prices. You are given tasks to complete and you generate Python code to solve them.
Generally, you follow these rules:
- ALWAYS RESPOND WITH PYTHON CODE
- ALWAYS RESPOND ONLY WITH CODE
- the python code is output directly to a file and ran.
- the code must consist of a function call "build_model" which accepts a parameter called "input_shape".
There are also requirements for the model:
- The model most produce a 1D shape using a Dense layer with 1 unit as the output.
- Use Keras to build the model.
- The function will take "input_shape" as a parameter and return the model to be used elsewhere in the python script.
- "input_shape" provided to the function will be in the following format: (window_size, feature_count).
- Only return the model in the function, do not fit the model.
- Do not include anything after the return.
- Compile the model before returning it.
"""
There is some requirements for the model that won’t change between runs, so these might as well be included in the system prompt.
Even with all the direct instructions specifying to only output python code, I am still getting code out with some summary or markdown wrapping the python code.
For sanity (and because I tried for many hours to get just output, I am stubborn and don’t want to change to a ML framework that supports Grammer) I am going to setup some regex to grab the code from markdown “if it exists”.
Generally if there is markdown there is summary, so this defeats two birds with one stone.
1
2
3
4
5
6
7
8
pattern_py = re.compile(r'```python\n(.*?)\n```', re.DOTALL)
def pythonize(input, pattern=pattern_py):
match = pattern.search(input)
if match:
output = match.group(1)
else:
output = input
return output
Training Loop
Now that all the parts are ready the training loop comes next, I am still working on the best way to “score” the model in order to update the model but RSME and MAE has worked in my testing.
A super easy way to test the model is to run another python script as a subprocess, and capturing any error output to deliver back to the LLM, which will use the error to make corrections and then running it through training again.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def train_model(epochs):
history = training_model.fit(x_train, y_train_close, validation_split=0.2, epochs=epochs, callbacks=[early_stopping])
training_model.save(f'./models/{model_preappend}_LSTM_1WEEKCHLG.keras')
# Generate Predictions for Training Data
predicted_values_close = training_model.predict(x_test)
print(predicted_values_close.shape)
rmse = np.sqrt(mean_squared_error(y_test_close, predicted_values_close))
mae = mean_absolute_error(y_test_close, predicted_values_close)
print(f"Test RMSE: {rmse}, Test MAE: {mae}")
return history, rmse, mae, predicted_values_close
train_model(1) # Train with one epoch quickly to make sure output of model is what we want
history, rmse, mae, predicted_values_close = train_model(1000000)
While the epoch count looks a bit crazy, and it is, there is an early stopping callback that detects when the model isn’t improving and stops the training.
1
early_stopping = EarlyStopping(monitor='val_loss', patience=50, restore_best_weights=True)
There is a lot of other parts in the script that aren’t super relevant to this post, mainly around the scaling and chunking of the data but I have chunked the data in the same way I want to use the model.
I want the model to predict 7 days out so I have chunked all the data into blocks of 7 days, nice and simple.
The training (and correction of errors) can be handled within a function
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def run_training(type: pyModels):
print("Training the model")
error_count = 0
process = subprocess.Popen("python zero_to_hero.py", shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
_, stderr = process.communicate()
if process.returncode != 0:
error_count+=1
print(f"An error occured: {error_count}" )
with open("error.txt", "w") as f:
f.write(str(stderr))
with open("model_ai.py", "r") as f:
code=f.read()
corrected = pyModels.correct_error(model_name, type.SYSTEM_PROMPT, code, stderr)
with open("model_ai.py", "w") as f:
f.write(corrected)
score = run_training(type)
with open("model_output.json", "r") as f:
score=f.read()
return score
And, finally, the loop! I am constructing an array of the top performing models that has been generated so far.
The array includes the code used as well as the score that was received.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
while (count != max_runs):
if count == max_runs: continue
print(f"Training Count {count}/{max_runs}")
prompt = pyModels.MLEngineer.SYSTEM_PROMPT
models.sort(key=lambda x: x['score']['MAE'])
models_for_thing = '<models>\n'
for m in models[:6]: # The LLM runs into problems if I increase this, framework/prompt issue for sure
print(m['score']['RSME'])
models_for_thing += '<model>\n'
models_for_thing += '<code>\n'
models_for_thing += f"{m['code']}\n"
models_for_thing += '</code>\n'
models_for_thing += '<score>\n'
models_for_thing += f"{ m['score']}\n"
models_for_thing += '</score>\n'
models_for_thing += '</model>\n'
models_for_thing += '</models>\n'
content = f''''
Review previous models and their score to see what decreased the RMSE and MAE values and what increased the values.
Rewrite and improve the model code to lower the RMSE and MAE values.
These are the top 3 performing models are ordered with the most successful first:
{models_for_thing}
'''
print(f'Content is length: {len(content)}')
rsp = pyModels.prompt(model_name, prompt, content)
output = pyModels.pythonize(rsp)
with open("model_ai.py", "w") as f:
f.write(output)
score = run_training(pyModels.MLEngineer)
_model = {'code': model_code, 'score': json.loads(score)}
models.append(_model)
# Increase count at the end
count+=1
The Training
To kick start the training I’ll get the LLM to generate a crappy little model that I want to perform badly, so that if the LLM is making improvements they can easily be seen.
1
2
3
4
5
rsp = pyModels.prompt(
model_name,
pyModels.MLEngineer.SYSTEM_PROMPT,
"Generate a simple LSTM model that can be quickly trained but not function well"
)
The first model it generates looks like this:
1
2
3
4
5
6
7
8
9
10
11
from keras.models import Sequential
from keras.layers import Dense, LSTM
def build_model(input_shape):
model = Sequential()
model.add(LSTM(units=64, activation='relu', input_shape=input_shape))
model.add(Dense(1,activation="linear")) #linear activation for regression problem
#compile the model
model.compile(optimizer='adam', loss = 'mean_squared_error')
return model
Now considering the size of the dataset this model should actually perform quite well, but it is a good starting place.
The output from the model looks like this: 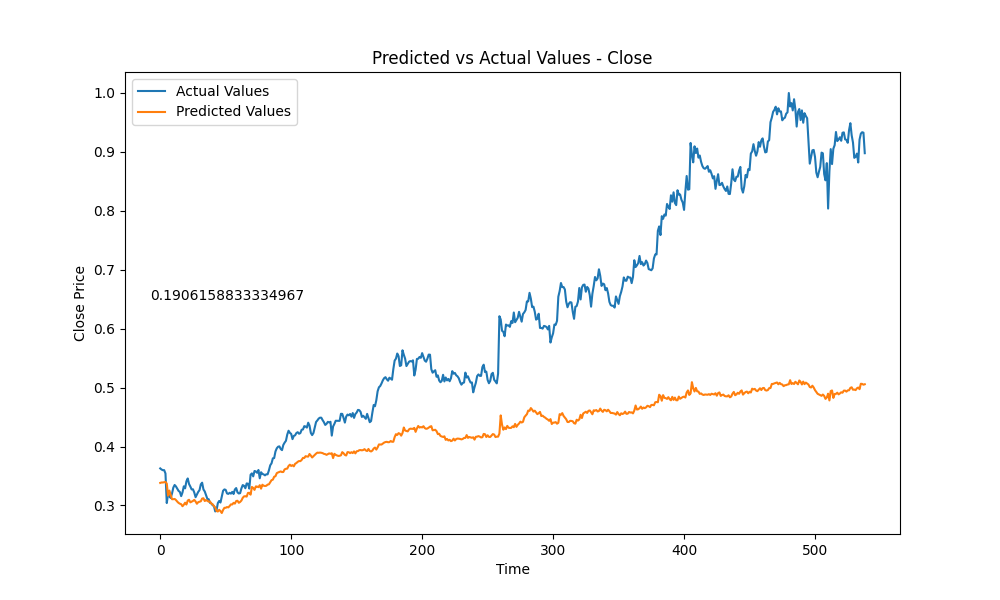 And that produced the MAE of score 0.1906158833334967.
And that produced the MAE of score 0.1906158833334967.
Here is a little slideshow after letting the training run for a couple hours, producing 177 amount of models.
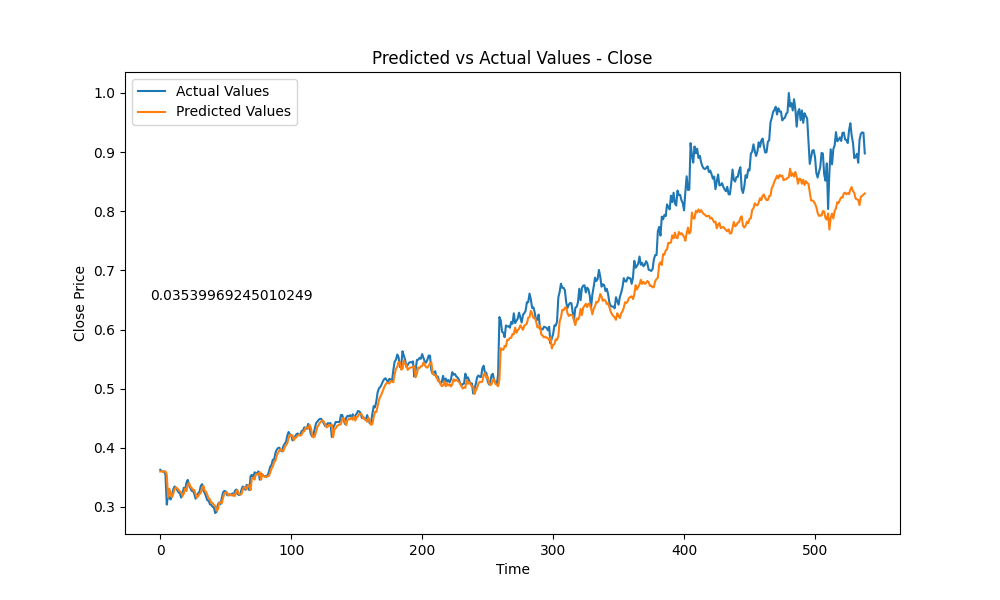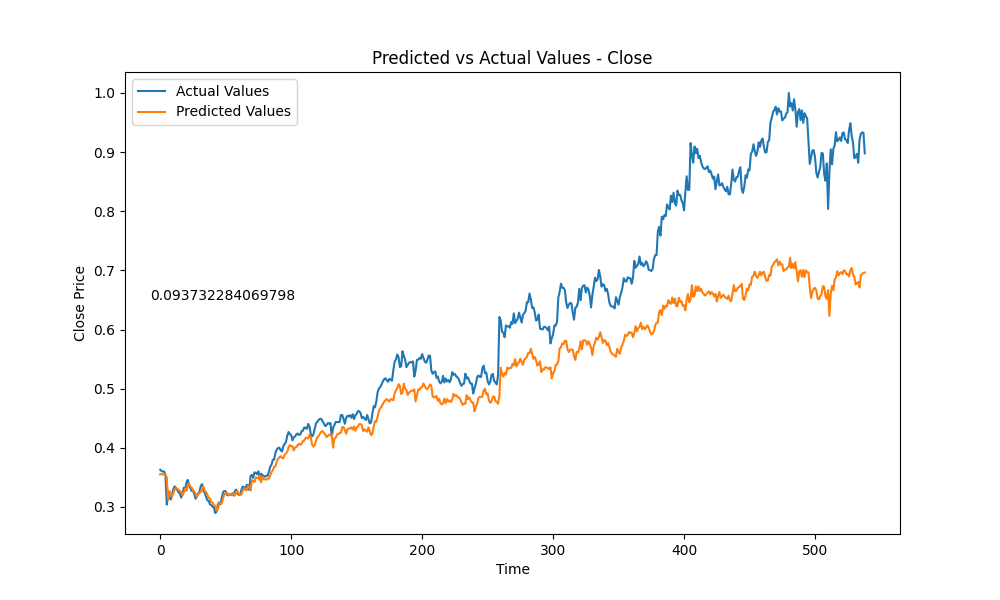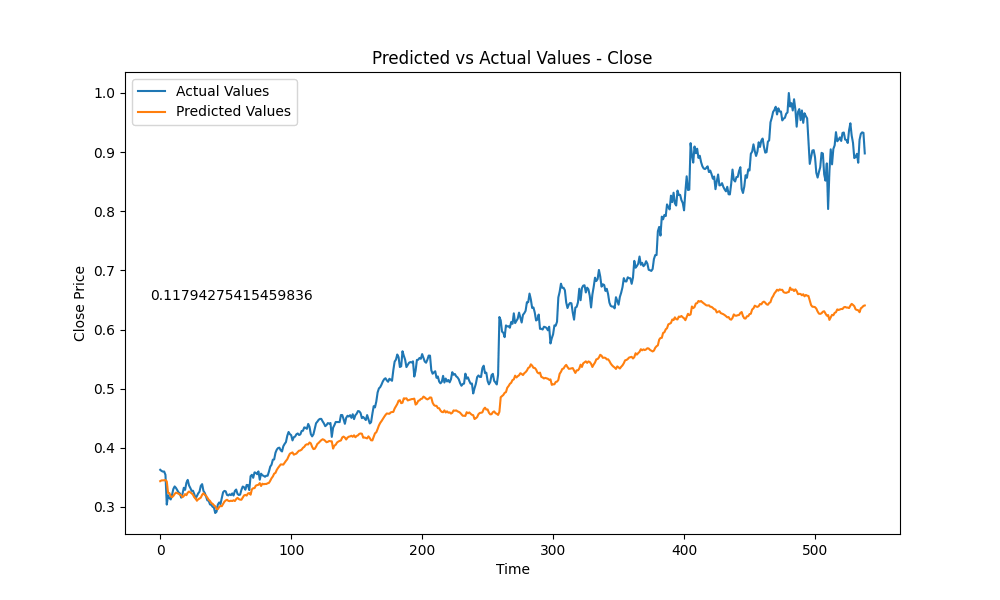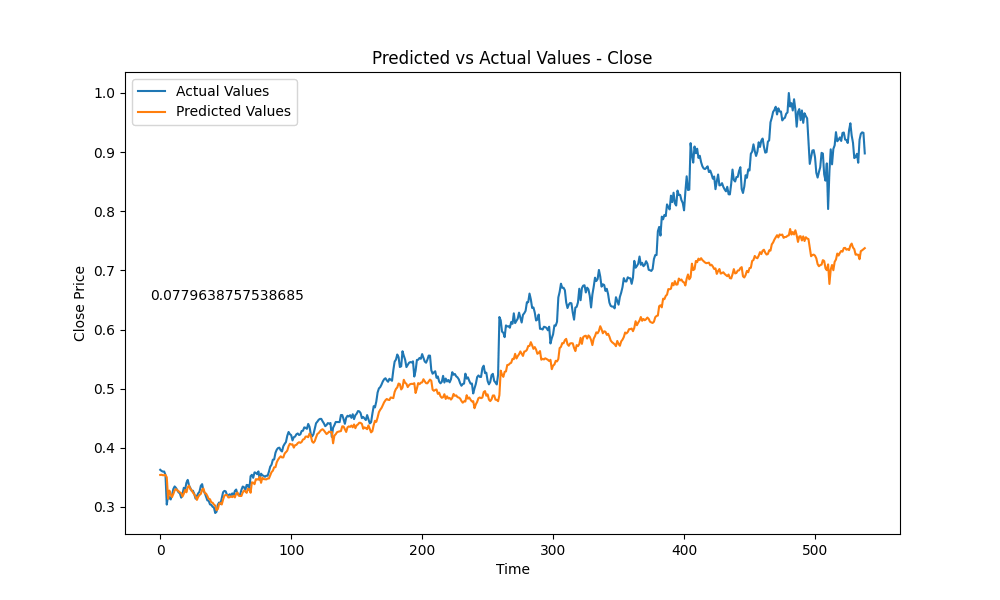
And the best model out of all is….. this guy here: 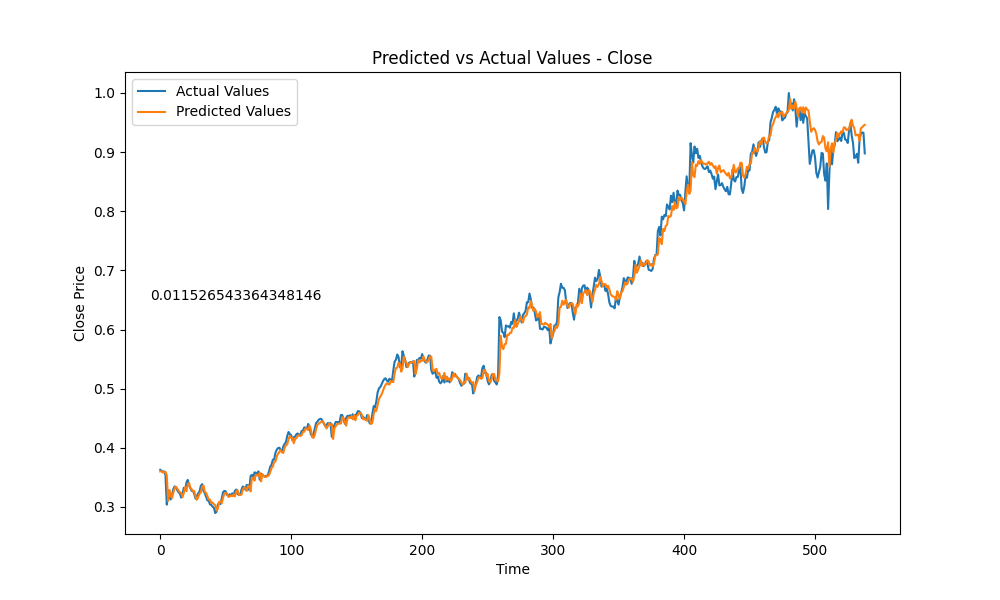
Conclusions
This is a good small scale example of including an LLM into a training loop for building other AI models.
Now this is still a very early state and isn’t tracking what really matters, the actual $$$ value that the model would have successfully predicted.
To make this model do anything other than lose money would take hundreds of hours of training and a massive increase in the available dataset, so please don’t go giving anything this model produces access to any sort of money or markets.
The smaller size of the LLM will also be limiting the model output, with more advanced modeling requiring a lot of higher order problem solving, possibly the new OpenAI o1 model could assist to further modify the peak performing models without needing the understanding of other models of the Keras library and python code.
There is also the problem of the framework I am using to run the model, Ollama.
While being nice and easy to use it does limit what I can do with context, conversations as well as just the general run time of the training. Ollama needs to load the LLM into memory each time I ask it to work on model, which is a big slow down in the process.
In the future using something like LangChain would open up what I can do with and how I can interact with an LLM.
The scoring is big problem, just tracking the MAE and RMSE is not going to produce a good model at the end on the day, but it is enough to see the LLM at work improving those values.