Creating an AWS Instance Scheduler

As much as I would love my Ec2 instances running 24/7, I just don’t have the budget, especially for larger instances that I may run.
Instead of tearing down the infrastructure and restoring it when it is required, which would create headaches with saving data and configuration, I am going to instead setup scheduling of my instances to spin them up and down at particular times.
AWS do provide a fully fleshed out solution, in the form of AWS Instance Scheduler but I want to have a go at writing up something of my own.
Using EventBridge Rules to schedule a run of a Lambda function seems to be the easiest way to approach this.
Then I can wrap that all up in a StackSet, which can be used to deploy to all accounts in the Organization I have setup.
I’ll use a DynamoDB table to store the schedules, so I can set instances to spin up and down at different times based on tagging of the instance.
 Infrastructure Design
Infrastructure Design
Getting Started
From my last post I now have a GitLab instance up and running, so I’ll create a new repository to setup the code for this project.
Once I have that created I can sync it down onto my machine using Git, then I’ll create a new Pulumi project inside a directory called infra:
1
2
3
git clone https://lab.betternet.online/better-networks/aws-task-scheduler.git
cd aws-task-scheduler
pulumi new aws-python --dir ./infra
Setting up Pulumi
This time I’ll leave the requirements file as is, there isn’t any new packages that are needed, because everything is going to be done entirely with AWS services.
There is a couple builtin packages that are required, in the __main__.py file replace everything with the following imports
1
2
3
4
5
6
import pulumi
import os
import json
import shutil
import hashlib
import pulumi_aws as aws
Secret tools we are going to use later ![]()
Building Out the Scheduler
There is a few components for the scheduler that needs to be built out.
- The DynamoDB Table
- The Lambda Function
- The StackSet Deployment
Surely those components are going to be super quick and easy to get going, with no foreshadowing at all.
Supporting Resources
Before we get into that can of worms though there is some supporting services that are needed for the rest of the deployment.
We need to get the details of the AWS Org, create a bucket for storing the files and a bucket policy to allow access from the accounts in the org.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
### Get the AWS Org details
org = aws.organizations.get_organization()
### Create a S3 bucket for storing the Lambda functions
bucket = aws.s3.Bucket(
"lambda-bucket",
acl="private",
)
### Bucket policy to allow read access from Org accounts
allow_org_access_bucket_policy = aws.iam.get_policy_document(
statements=[
aws.iam.GetPolicyDocumentStatementArgs(
principals=[
aws.iam.GetPolicyDocumentStatementPrincipalArgs(
type="*",
identifiers=["*"]
)
],
actions=[
"s3:GetObject",
"s3:ListBucket",
],
resources=[
bucket.arn,
bucket.arn.apply(lambda arn: f"{arn}/*"),
],
conditions=[
aws.iam.GetPolicyDocumentStatementConditionArgs(
# Adds the OrgID to the conditional statement
test="StringEquals",
variable="aws:PrincipalOrgID",
values=[org.id]
)
],
)
]
)
### Attaching the above policy to the bucket
bucket_policy = aws.s3.BucketPolicy(
"allowAccessFromOrg",
bucket=bucket.id,
policy=allow_org_access_bucket_policy.json
)
Allowing the other accounts access to a central bucket cuts down on management and cost, there is only one copy of the lambda function code to manage and pay for.
The Table
The next lego piece is the DynamoDB Table, being the low hanging fruit on the list of components.
1
2
3
4
5
6
7
8
9
10
11
## The Table
table_schedule = aws.dynamodb.Table(
"instance-scheduler-table",
attributes=[
aws.dynamodb.TableAttributeArgs(
name="ScheduleName",
type="S"
)],
billing_mode="PAY_PER_REQUEST",
hash_key="ScheduleName",
)
The Hash Key will be the name of the Schedule, nice and simple.
Also setting the billing mode to PAY_PER_REQUEST, the application will only be running every 30 minutes or so, provisioning capacity would be overkill (and a waste of money).
To allow the organization accounts to assume the role in the management account and read the DynamoDB Table, every account ID needs to be added in the Assume Policy of the role.
While I tried for a while to allow the every account in the Org by using Org ID, that just isn’t support yet ![]() .
.
Later I am going to have to either build something event driven into the Scheduler to add new Org Accounts as they are added or create an IAM User and push out the credentials, but for now just running the pulumi project will be enough to update the list.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
## The role
schedule_role = aws.iam.Role(
"OrgDdbScheduler",
assume_role_policy=json.dumps({
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Principal": {
# Allow all accounts in the Org to assume the role
"AWS": [_acc.id for _acc in org.accounts]
}
}
]
})
)
# Allow the role to get, query and scan items from the Table
schedule_policy = aws.iam.RolePolicy(
"OrgDdbSchedulerPolicy",
role=schedule_role.name,
policy=pulumi.Output.json_dumps({
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"dynamodb:BatchGetItem",
"dynamodb:GetItem",
"dynamodb:Scan",
"dynamodb:Query",
],
"Resource": table_schedule.arn
}
]
})
)
The Function
Now comes the can of worms, the Lambda function that checks the schedule against the all the instances in an account and either stops or starts them.
I’ll be the first to admit that I fully didn’t understand the scope of this project before I started, getting stuck on the Lambda function for an unfunny amount of time, considering at the start I thought it would only take 5 minutes!
Being one of the first times building out a function it was a learning experience and a half, particularly writing the code to be more memory (and time!) efficient.
If you haven’t guessed the Lambda will be written in Python.
The function is going to be created in it’s own folder, to make it easier to ZIP up later for deployment.
1
2
mkdir lambda/ScheduleRunner
touch lambda/ScheduleRunner/lambda_function.py
Because the Lambda function is a little large I’ll break it down into sub-components.
Imports
Always going for the low hanging fruit, the imports!
1
2
3
4
import json
import boto3
import os
from datetime import datetime
Nice and easy, nothing too crazy.
Supporting Functions
There are only 2 functions that are going to be used within the Lambda.
One to check whether the current time is inside or outside the schedule and one to reverse the requested state if outside the schedule:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
### Supporting functions
## Check if inside current scheduled time
def inside_schedule(now, schedule):
start_time = datetime.strptime(schedule['StartTime'], "%H%M").time()
end_time = datetime.strptime(schedule['EndTime'], "%H%M").time()
if start_time <= end_time:
# Case when end time is on the same day
return start_time <= now <= end_time
else:
# Case when end time is on the next day
return start_time <= now or now <= end_time
## Reverse the requested state if outside the schedule
def reverse_state(current_state):
state_mapping = {
"running": "stopped",
"stopped": "running",
}
return state_mapping[current_state]
And a simple check that runs the core function so I can test it locally:
1
2
3
## Used for locally testing before deploying Lambda to AWS
if __name__ == "__main__":
lambda_handler({"Test": "Nothing"},{"Test": "Nothing"})
Global Variables
Although this Lambda function won’t be in the situation where there is an existing execution environment it can use (the time period between runs is way too large), I still like coding the function like it would.
This just keeps it as a practice that I continue to do automatically ![]() .
.
First I setup the the boto3 clients for the resources I need:
1
2
ec2 = boto3.client('ec2')
sts = boto3.client('sts')
Because I am parsing states from the DynamoDB table I want to make sure I am only dealing with states I have coded for:
1
2
3
4
5
### Limit what can be a state
acceptedStates = [
"running",
"stopped"
]
And finally I will build out a list of regions to loop through and check for Ec2 instances:
1
2
regions = [region['RegionName'] for region in ec2.describe_regions()['Regions']]
print(regions)
This is what the output of the print('regions') looks like (it’s a bit small, click the image to enlarge it).

Output from the Python Function
Lambda Handler
Everything I am going to talk about in this section is under the following function:
def lambda_handler(event, context):
This is where all the magic happens, it is a semi-large function so I’ll also break it down further into blocks.
The first block is going to use STS assume to assume a role in the management account and then setting up a DynamoDB Boto3 client with those assumed credentials:
1
2
3
4
5
6
7
8
9
10
11
12
### Assume the role to access the DDB table in the management account
assumed_role = sts.assume_role(
RoleArn=os.environ.get('DDB_ROLE'),
RoleSessionName='AssumeRoleSession'
)
ddb = boto3.resource(
'dynamodb',
aws_access_key_id=assumed_role['Credentials']['AccessKeyId'],
aws_secret_access_key=assumed_role['Credentials']['SecretAccessKey'],
aws_session_token=assumed_role['Credentials']['SessionToken']
)
table = ddb.Table(os.environ.get('DDB_TABLE'))
Then I’ll use the DynamoDB client to fetch the schedules from the table:
1
2
3
4
5
6
7
8
9
10
11
## Load in schedules from DynamoDB
response = table.scan()
_schedules = response['Items']
# If there ends up being a large number of schedules DynamoDB may paginate
while 'LastEvaluatedKey' in response:
response = table.scan(ExclusiveStartKey=response['LastEvaluatedKey'])
_schedules.extend(response['Items'])
if not _schedules: # If no schedules have been fetched from the table exit the function
print("No schedules have been loaded, exiting")
return { 'statusCode': 404, 'body': 'no_schedules'}
print(_schedules)
One major benefit of using DynamoDB is that fact it is NoSQL, so the schema can be changed as the application evolves without having to update the actually schema of the database (like a standard SQL system).
So far the schema of the schedules looks like this, using the Default schedule as the example:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
{
"ScheduleName": {
"S": "Default"
},
"EndTime": {
"S": "1300"
},
"StartTime": {
"S": "2130"
},
"State": {
"S": "running"
}
}
At this stage all times are in UTC, so I have to convert from my timezone to UTC to get the instances running at the right time.
The schedule defines a start time and an end time, plus what the state of the instance should be during that time period.
After fetching those I’ll go through the list of schedules and figure out if the schedule is active and what state instances tagged with the schedule should be:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
schedules = {}
now = datetime.now().time()
print(now) # Time is in UTC
for schedule in _schedules:
# Make sure state is one in the list
if schedule['State'] not in acceptedStates:
print("Unknown requested state")
continue
schedules[schedule['ScheduleName']] = {}
if inside_schedule(now, schedule):
schedules[schedule['ScheduleName']]['State'] = schedule['State']
else:
schedules[schedule['ScheduleName']]['State'] = reverse_state(schedule['State'])
print(schedules)
The end result will be a python dictionary that will have the name of the schedule as a key and what State the schedule calls for.
Finally I’ll loop through all the regions I grabbed earlier, get all the instances in every region, check the schedule tag (and apply the default schedule if incorrectly tagged or no tag), comparing the current state against the wanted state and then correcting the state if they differ.
What a mouthful! Hopefully the code is easier to understand.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
### Get all instances in all regions and check against schedule
for region in regions:
instances = {}
print("Checking region: " + region)
# Change Boto3 session to the region currently being checked
session = boto3.Session(region_name=region)
ec2_session = session.client('ec2')
response = [item['Instances'] for item in ec2_session.describe_instances()['Reservations']]
# If there is no response (no instances) continue in the loop
if not response: continue
for item in response:
for inst in item:
instances[inst['InstanceId']] = {}
instances[inst['InstanceId']]['State'] = inst['State']['Name']
instances[inst['InstanceId']]['Schedule'] = 'Default'
for tag in inst['Tags']:
if tag['Key'] == "Schedule": instances[inst['InstanceId']]['Schedule'] = tag['Value']
### Perform the action to complete on the instance (start,stop,null)
for i in instances:
print(instances[i])
if instances[i]['State'] != 'terminated':
if instances[i]['State'] != schedules[instances[i]['Schedule']]['State']:
match schedules[instances[i]['Schedule']]['State']:
case 'running':
print("Starting Instance: " + i)
ec2.start_instances(InstanceIds=[i])
case 'stopped':
print("Stopping Instance: " + i)
ec2.stop_instances(InstanceIds=[i])
The Deployment
The easiest option to deploy out the Lambda Function and other resources to all accounts in the Organization is with StackSets.
Unfortunately StackSets can’t deploy Pulumi code, and I don’t want to setup CodePipeline, so I’ll have to write up some Cloudformation to deploy ![]() .
.
There are a couple different formats that Cloudformation can accept, either JSON or YAML, but I haven’t worked with the JSON variety so that is the format of choice for this project.
Instead of writing out a super large file in the main Pulumi project I am going to use the power of Python and load the JSON in from a separate file.
1
touch stackset-template.json
I am not going to go through the whole file, just some key components.
Here is the file in it’s entirety if you want to look through it all.
The parameters are pretty self explanatory, apart from SchedulerS3Key, which is the file path to the ZIP file in the S3 bucket:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
"Parameters": {
"BucketArn": {
"Type": "String",
"Description": "BucketArn"
},
"BucketName": {
"Type": "String",
"Description": "BucketName"
},
"SchedulerS3Key": {
"Type": "String",
"Description": "SchedulerS3Key"
},
"OrgDdbSchedulerTable": {
"Type": "String",
"Description": "OrgDdbSchedulerTable"
},
"OrgDdbSchedulerRole": {
"Type": "String",
"Description": "OrgDdbSchedulerRole"
}
}
Cloudformation needs to know what bucket to get the ZIP file from, as well the role to access the DynamoDB table and the name of the table.
The EventBridge Rule is the start of the entire process, it triggers the Lambda at a set rate.
I don’t really need minute by minute schedules, running every 30 minute suits me just fine.
1
2
3
4
5
6
7
8
9
10
"30mEventRule": {
"Type": "AWS::Events::Rule",
"Properties": {
"ScheduleExpression": "rate(30 minutes)",
"Targets": [{
"Arn": { "Fn::GetAtt": ["SchedulerLambda", "Arn"] },
"Id": "SchedulerLambda"
}]
}
}
It has the Lambda function set as the target, which is defined later in the file (yay for automatic resolution of dependencies).
There is also the Lambda function role which has the permissions to read region and instance info (describe) as well as stopping and starting instances.
The key part of the role is the permission to assume the DynamoDB role in the management account, Referencing the role ARN that gets passed to the stack:
1
2
3
4
5
6
7
8
9
10
11
{
"PolicyName": "LambdaExecutionPolicy",
"PolicyDocument": {
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": {"Ref": "OrgDdbSchedulerRole"}
}]
}
}
The Lambda resource isn’t too special either, I did have to increase the timeout and memory from the default of 3 seconds and 256mb to 30 seconds and 512mb.
The timeout is just long enough to run through all the regions but it may need to be increased in the future if there are a lot of instances to manage.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
"SchedulerLambda": {
"Type": "AWS::Lambda::Function",
"Properties": {
"Handler": "lambda_function.lambda_handler",
"Role": {
"Fn::GetAtt": [ "SchedulerLambdaRole", "Arn" ]
},
"Code": {
"S3Bucket": {"Ref": "BucketName"},
"S3Key": {"Ref": "SchedulerS3Key"}
},
"Runtime": "python3.12",
"Timeout": 30,
"MemorySize": 512,
"Environment": {
"Variables": {
"DDB_TABLE": {"Ref": "OrgDdbSchedulerTable"},
"DDB_ROLE": {"Ref": "OrgDdbSchedulerRole"}
}
}
}
}
Putting it all Together
Now the fun part, combining all the components together into a working solution, so back to the Pulumi project!
The Lambda function needs to be zipped up and uploaded into the S3 bucket, I first zipped the file then renamed it to the MD5 of the file.
This will ensure that any changes to the Lambda function or other files in that directory force an update of the Lambda functions in the accounts by changing SchedulerS3Key:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
### Create ZIP of the Lambda function
shutil.make_archive("lambda", "zip", "./lambda/ScheduleRunner")
os.rename("./lambda.zip", "./temp/lambda.zip")
## Get the MD5 of the ZIP and rename it
with open("./temp/lambda.zip", "rb") as f:
contents = f.read()
hash_md5 = hashlib.md5(contents).hexdigest()
os.rename("./temp/lambda.zip", "./temp/" + hash_md5 + ".zip")
## Upload the ZIP file to the S3 bucket
file_to_upload = pulumi.FileAsset("./temp/" + hash_md5 + ".zip")
bucket_object = aws.s3.BucketObject(
"scheduledTask", bucket=bucket.id, key=hash_md5 + ".zip", source=file_to_upload
)
If it worked (which it always does for me ![]() ), there will a directory called temp with files that look like the following.
), there will a directory called temp with files that look like the following.

Temp Directory with Lambdas Zipped I had run the program a couple times, so I have a few files in the directory.
Now everything can be taken and a StackSet resource can be created with the parameters I talked about before:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
### The Stackset
scheduler = aws.cloudformation.StackSet(
"scheduler",
permission_model="SERVICE_MANAGED",
auto_deployment=aws.cloudformation.StackSetAutoDeploymentArgs(enabled=True),
parameters={
"BucketArn": bucket.arn,
"BucketName": bucket.bucket,
"SchedulerS3Key": hash_md5 + ".zip",
"OrgDdbSchedulerTable": table_schedule.name,
"OrgDdbSchedulerRole": schedule_role.arn
},
# This line reads in the Cloudformation template
template_body=open("stackset-template.json").read(),
capabilities=["CAPABILITY_IAM"],
)
The StackSet needs to be told where to deploy the stacks:
1
2
3
4
5
6
7
8
9
10
### The stackset deployment
scheduler_instance = aws.cloudformation.StackSetInstance(
"scheduler",
deployment_targets=aws.cloudformation.StackSetInstanceDeploymentTargetsArgs(
organizational_unit_ids=[
org.roots[0].id,
],
),
stack_set_name=scheduler.name,
)
And the default schedule needs to be created.
I have yet to decide the bet way to get schedules into the DynamoDB Table but this will work perfectly fine for now:
1
2
3
4
5
6
7
8
9
10
### The stackset deployment
scheduler_instance = aws.cloudformation.StackSetInstance(
"scheduler",
deployment_targets=aws.cloudformation.StackSetInstanceDeploymentTargetsArgs(
organizational_unit_ids=[
org.roots[0].id,
],
),
stack_set_name=scheduler.name,
)
The End Result
After running pulumi up I can see the DynamoDB Table and S3 bucket has been created, with the lambda function uploaded successfully:
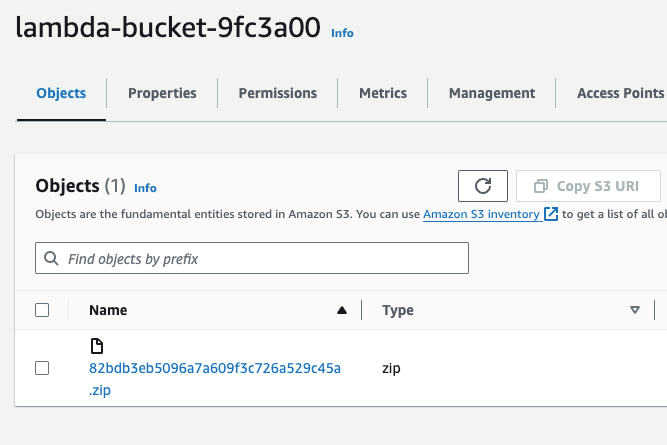 S3 Bucket with Lambda Zip
S3 Bucket with Lambda Zip
As well as the StackSet with the successful Stack Instances deployed in my Org accounts (just 2 at this stage):
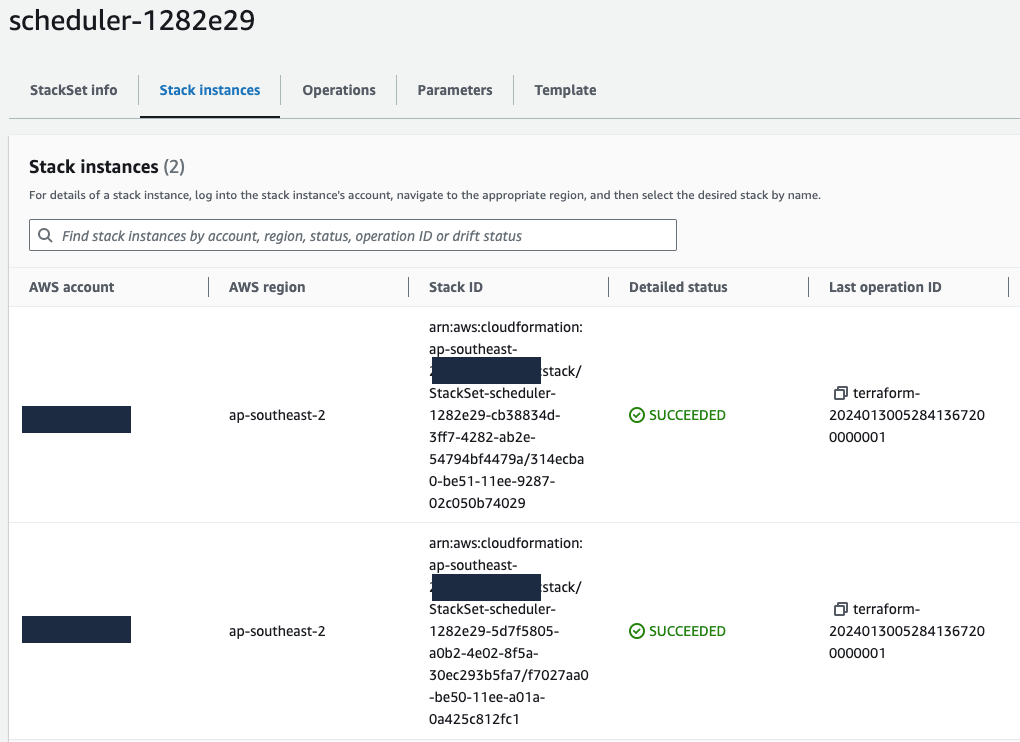 StackSet Instances
StackSet Instances
And inside both accounts the EventBridge Rule and Lambda have been created:
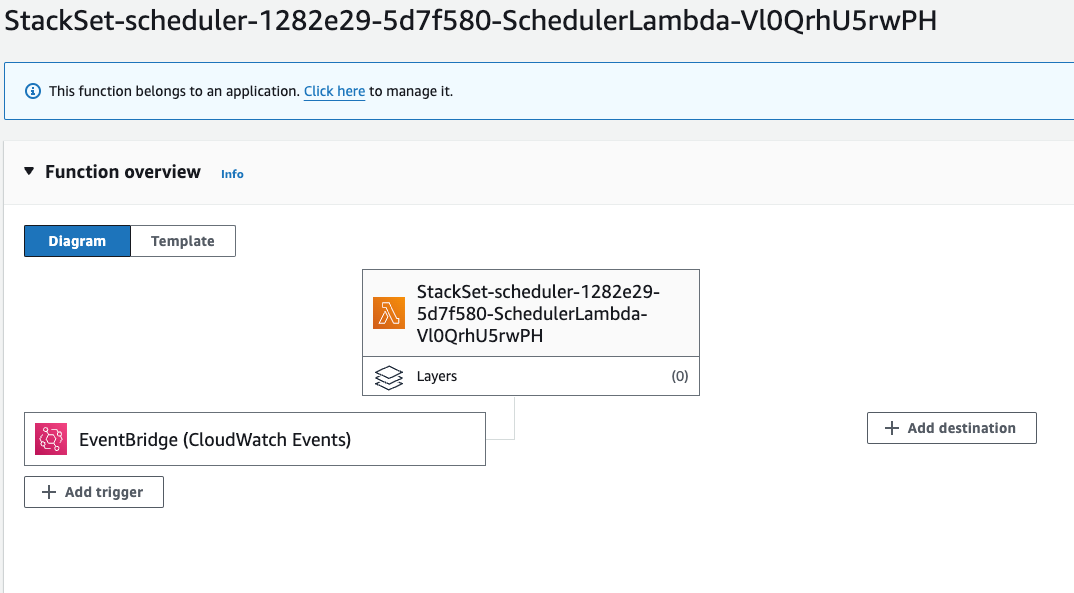 Scheduler Lambda Function
Scheduler Lambda Function
Finally, after leaving the Scheduler running overnight I can go and check the CloudWatch logs and in the correct log, after the schedule start-time, the instance is started!
Schedule loaded > [{‘EndTime’: ‘1300’, ‘ScheduleName’: ‘Default’, ‘State’: ‘running’, ‘StartTime’: ‘2130’}]
Requested state of the schedule > {‘Default’: {‘State’: ‘running’}}
The instance start and the schedule > {‘State’: ‘stopped’, ‘Schedule’: ‘Default’}
Action taken against instance > Starting Instance: i-06b13b8d6d619dc64
Conclusion
And that is it, my instances now just need a tag called Schedule with the name of a schedule, or I can just leave them and the default will apply.
This is going to save me a lot of money, I am constantly forgetting to stop instances outside of times I would use them.
There are a couple areas that’ll need improvement and are on the to-do list. The primary one is access to the DynamoDB table with the IAM role, updating the accounts that are allowed to assume the role is currently a manual process.
This could be remediated by either an EventDriven process to add new accounts in or by creating an IAM User and pushing the credentials into Secrets Manager, which I am leaning more towards.
I would also like to add the ability to only have the instances running on particular days, which shouldn’t be super hard to add in the near future.
Also forgetting that my instances didn’t have an EIP, so the Cloudflare DNS records becomes orphaned to the old IP after the instance is stopped…. Not the fault of the Scheduler and more the fault of my infrastructure setup, not very good for security!
I didn’t like that fact that during testing I when deleted the Lambda function manually, the Cloudformation stack got caught in Rollback Hell, so I ended up having to delete the whole stack and recreated it.
Although I did try creating a Lambda function with the same name, I had it set to NodeJS instead of Python, which didn’t get changed when the stack ran ![]() .
.
I thoroughly enjoyed breaking in and creating this task scheduler but I wouldn’t recommend running it in production.
The AWS variant is a much better choice for use in critical projects.